
If you're working with data in Python Pandas, you may find yourself needing to drop duplicate rows across multiple columns. This can be a tricky task, but luckily there are a few different ways to go about it. In this blog post, we'll explore how to drop all duplicate rows and how to drop duplicate rows across multiple columns in Python Pandas.
Drop duplicates method
The first and the easiest way to remove duplicate rows in your Pandas Dataframe is to use the drop_duplicates() method.
Pandas drop_duplicates() method returns Dataframe with duplicate rows removed.
Syntax:
DataFrame.drop_duplicates(subset=None, *, keep='first', inplace=False, ignore_index=False)
By default, this method removes duplicate rows based on all columns. So if you simply need to delete all duplicate rows from the Dataframe you can use df.drop_duplicates() without specifying parameters. Please note that if you want to modify Dataframe inplace you will need to specify inplace parameterdf.drop_duplicates(inplace=True).
Example: Delete all duplicate rows from the Dataframe
Let's create a Dataframe with some duplicate rows.
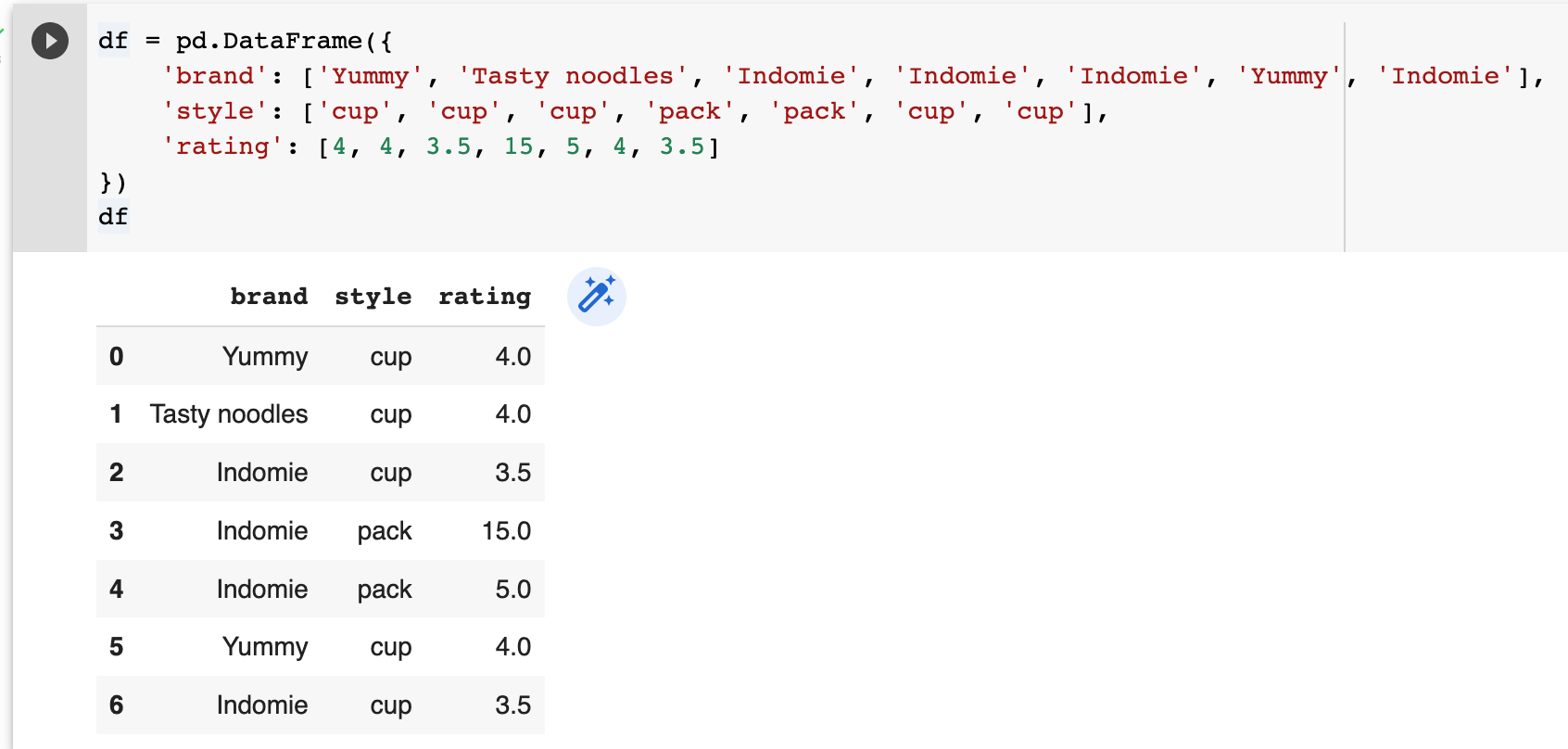
In this Dataframe row 0 is a duplicate of row 5, and row 2 is a duplicate of row 6. So when you use the df.drop_duplicates() method, those duplicates will be removed.
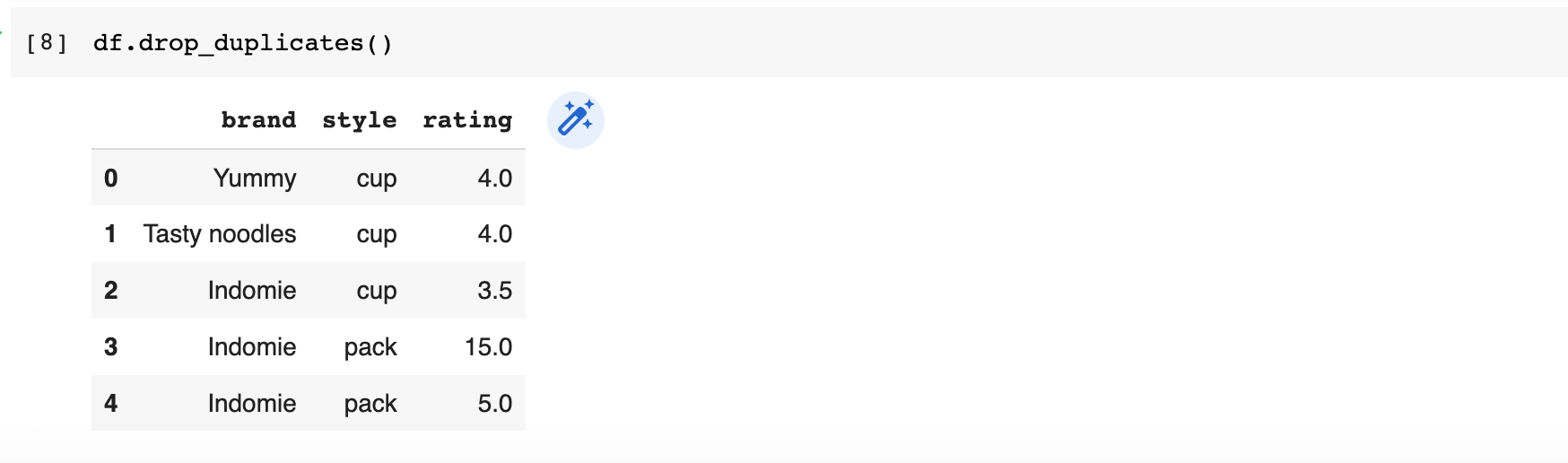
However if you need to drop duplicate rows across specific column(s), use subset.
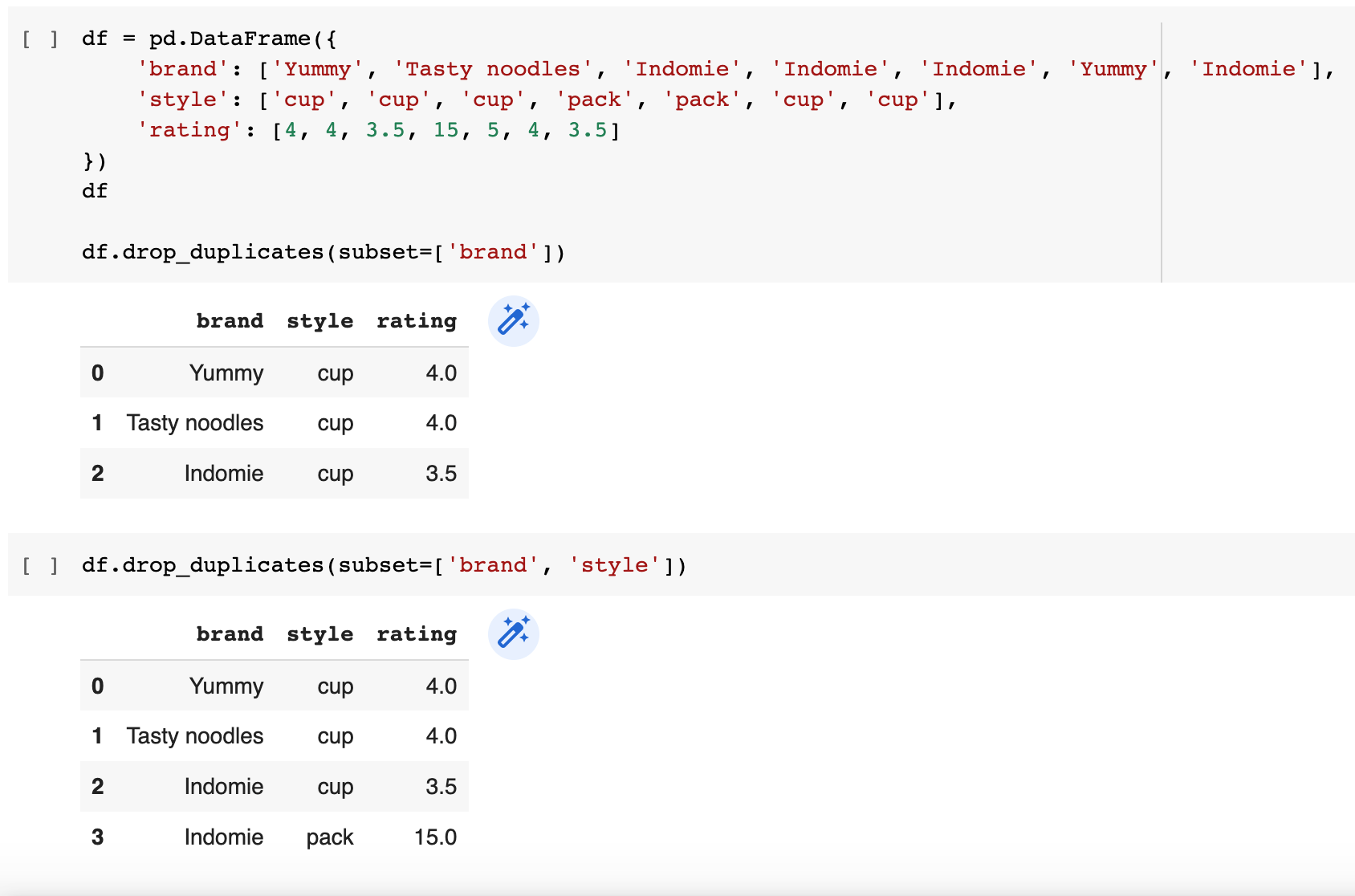
Your subset can be one column if you want to identify duplicates in this one specific column and keep first ocurance.
df.drop_duplicates(subset=['Your Column'])
Or it can contain multiple columns that you want to use to identify duplicates.
df.drop_duplicates(subset=['Your Column 1', 'Your Column 2' ])
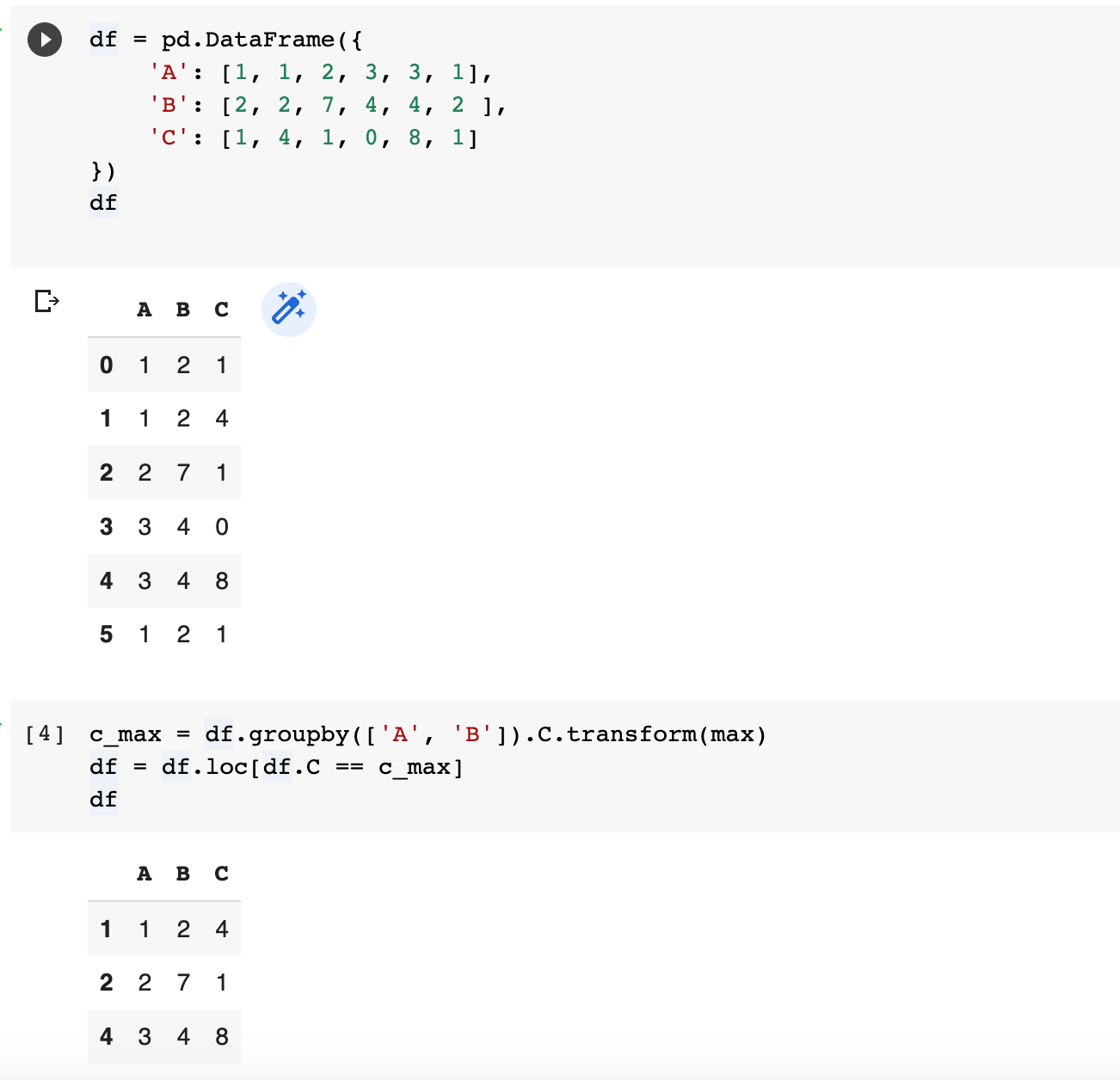
Groupby() method
The second way to drop duplicate rows across multiple columns is to use the df.groupby() method.
Lets have a look at the Pandas Dataframe which contains duplicates values according to two columns (A and B) and where you want to remove duplicates keeping the row with max value in column C. This can be achieved by using groupby method.
Identify duplicate rows with df.duplicated()
You may also find useful to know about about df.duplicated()which returns boolean series denoting duplicate rows.
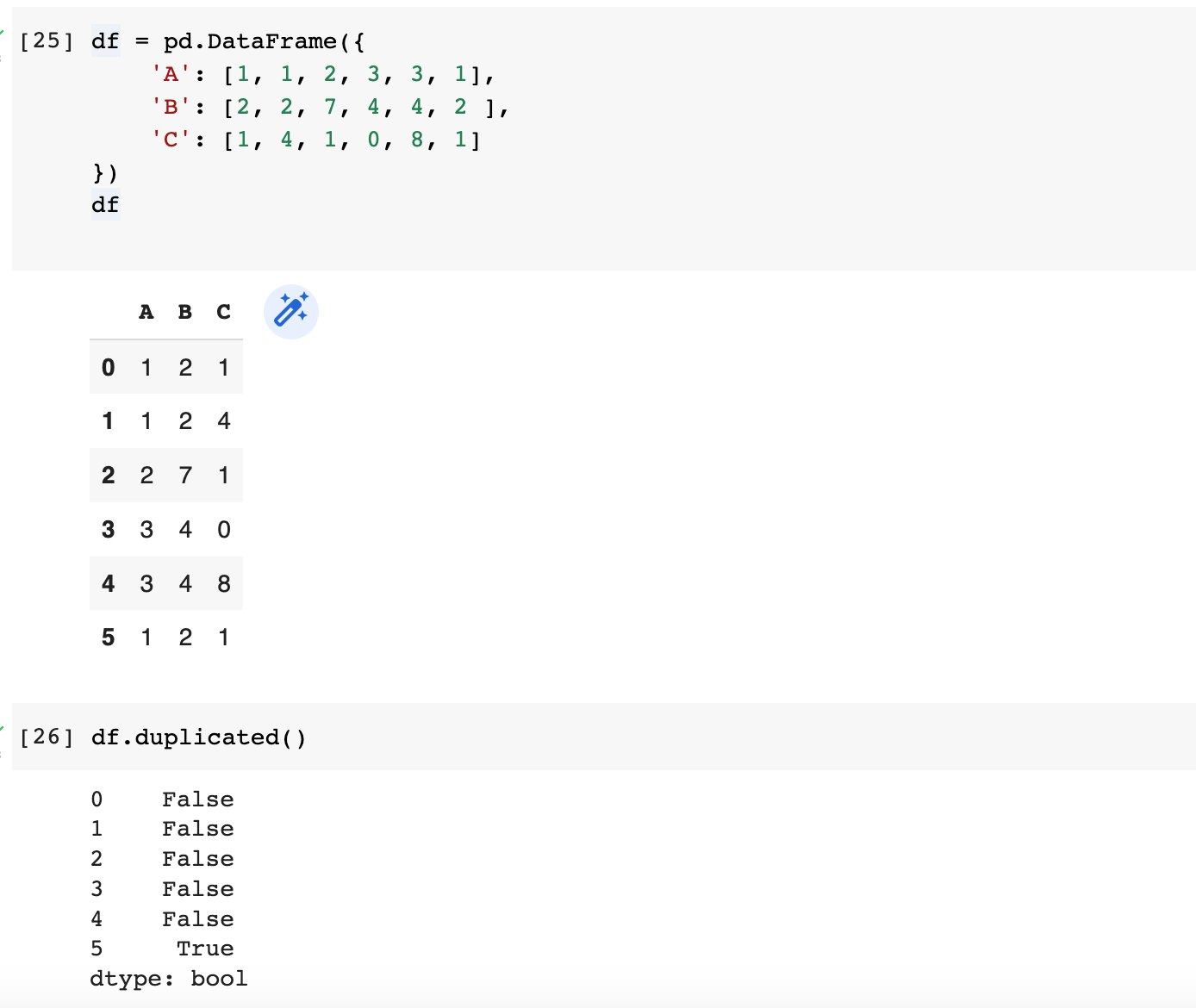
df.duplicated() to identify duplicate rowsBy default, for each set of duplicated values, the first occurrence is set on False and all others on True.
By using one of these methods, you can easily drop all duplicate rows across multiple columns in Python Pandas. With a few lines of code, you can quickly and easily clean up your data and make sure that it is accurate and up-to-date.