
If you’re a data scientist or analyst, you know how important it is to be able to extract data from websites. Fortunately, Python makes it easy to do this with the Pandas library. In this blog post, we’ll look at how to scrape tables from websites in Python using Pandas pd.read_html().
The Pandas read_html() function is an efficient and convenient way to convert an HTML table into a Pandas DataFrame. This tool can be beneficial for quickly importing tables from various websites without having to figure out how to scrape the HTML. Utilizing Pandas read_html is simple and works well with uncomplicated tables, such as those on Wikipedia pages. However, there can be some challenges when using this function on websites that do not welcome scraping and with its formatting.
The pd.read_html() function takes a URL as an argument and returns a list of Dataframe objects, each of which contains the data from a single table. To use it, you will need to import the Pandas library.
import pandas as pd
Once you have imported Pandas, you can use the read_html() function to extract tables from a website. For example, if you wanted to extract tables from the Wikipedia page for the 2020 Summer Olympics, you could use the following code:
tables = pd.read_html("https://en.wikipedia.org/wiki/2020_Summer_Olympics")
or you can do the same in two lines using the following code:
url = 'https://en.wikipedia.org/wiki/2020_Summer_Olympics'
tables = pd.read_html(url)
Please note that this code extracts all tables available from the URL. You can check the number of tables captured from the page using:
print(f'Total tables: {len(tables)}')
Lets see how many tables are on the Wikipedia page for the 2020 Summer Olympics.

The above tells us that there are nineteen tables on the page. Now, you may be wondering how to scrape the specific table from the page. You will need to inspect all scraped tables by using an index. Tip: "tables" is the list of dataframes returned by Pandas. You can get the first dataframe in the list of dataframes using tables[0].
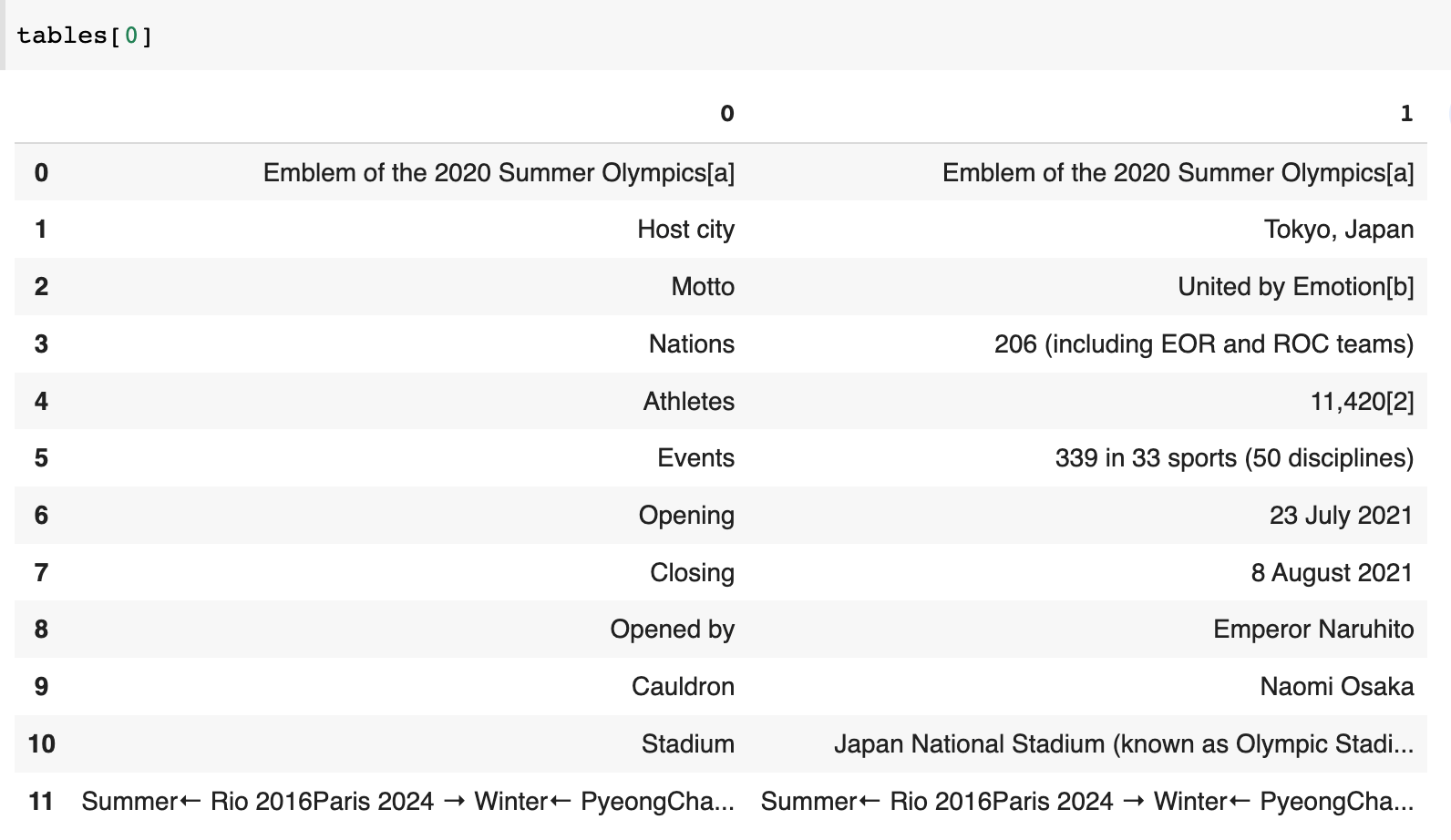
This data comes from the table called "Games of the XXXII Olympiad".

If you want to extract the table called "2020 Summer Olympics medal table," you can inspect all tables and identify that the table was assigned index 7 tables[7]. However, this is not an effective way of scraping the table from the page. Instead, you can make the table selection easier by using the match parameter to select a subset of tables. We can use the caption “2020 Summer Olympics medal table” to select the table.
url = 'https://en.wikipedia.org/wiki/2020_Summer_Olympics'medal_table = pd.read_html(url, match=''2020 Summer Olympics medal table'')
print(medal_table)
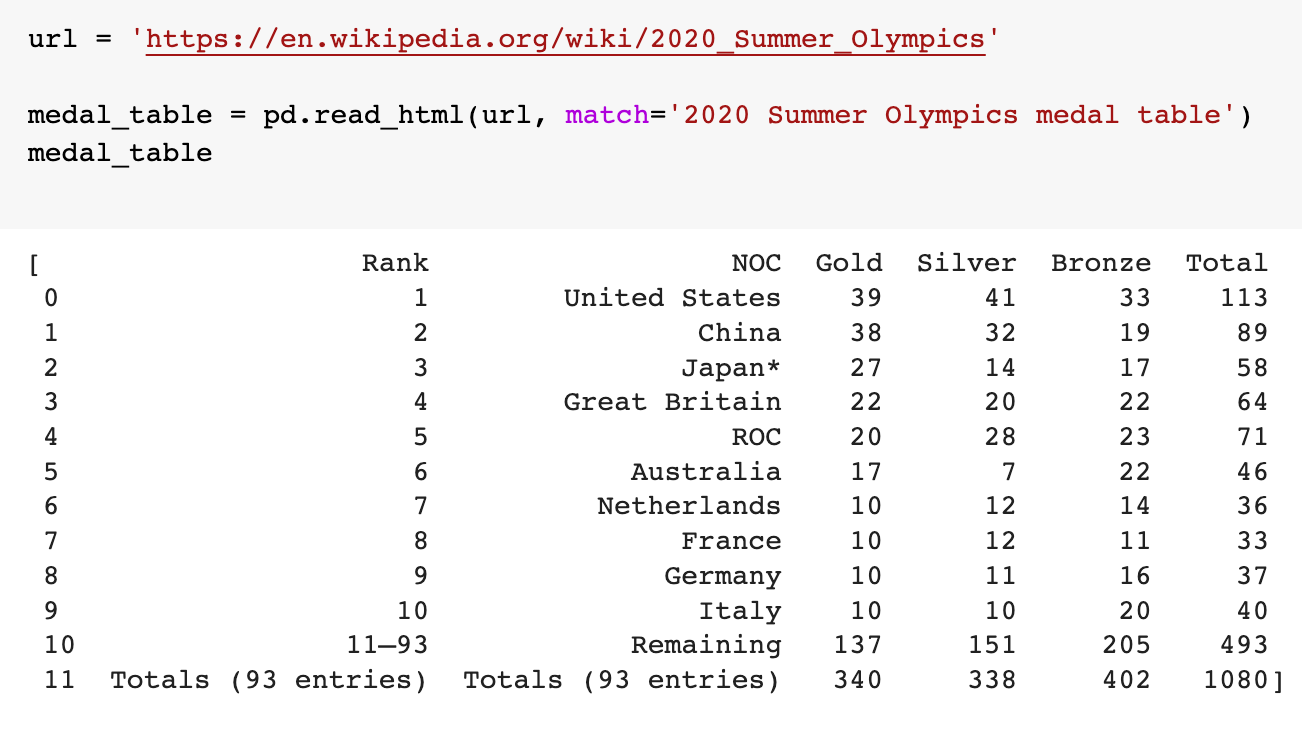
This gives us the data we wanted from the table called "2020 Summer Olympics medal table".
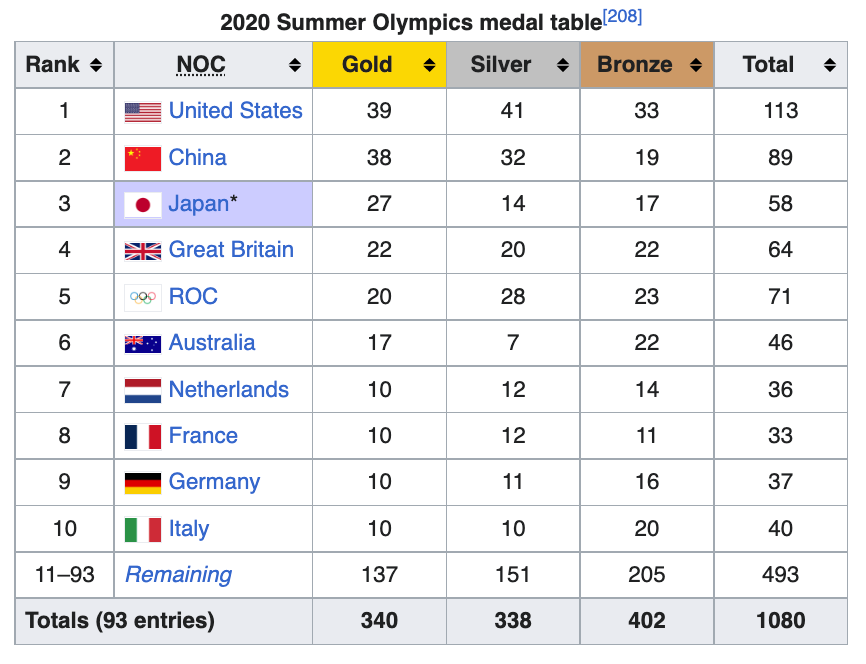
Now you can save the table as a csv file using the following code:
df = medal_table[0]
df.to_csv('medal_table.csv')
Full Solution
import pandas as pd
url = 'https://en.wikipedia.org/wiki/2020_Summer_Olympics'
tables = pd.read_html(url)
#prints number of tables found on the page
print(f'Total tables: {len(tables)}')
#check first which index was assigned to the table you are after
#in this case "2020 Summer Olympics medal table" has index 7
#alternatively you can use match parameter to get one table
df = tables[7]
#save to csv file
df.to_csv('Olympics2020_medal_table.csv')Pandas read_html() and error 403
This function works well on Wikipedia pages, but not on websites that don't welcome scraping. Therefore, you are likely to run into error 403 "HTTPError: HTTP Error 403: Forbidden". Here is how to get around this problem: use the requests library together with pandas.
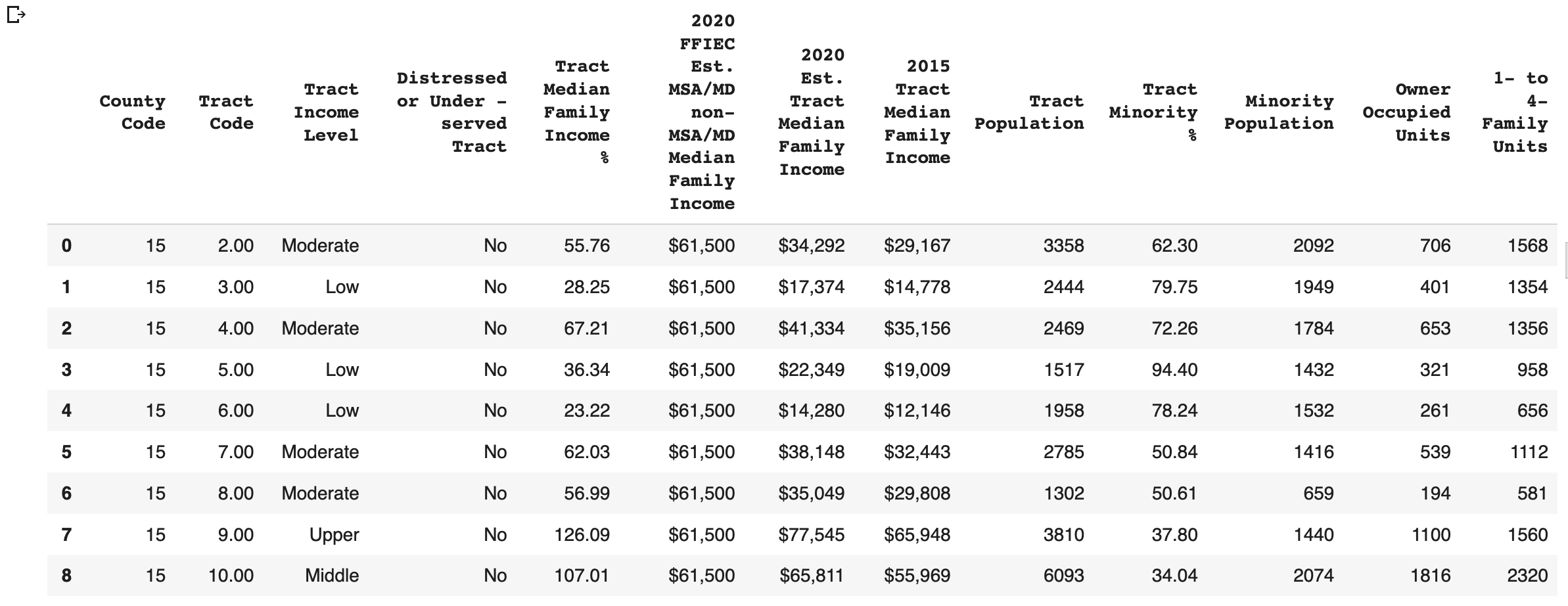
For example, if you try to scrape the table called "2020 FFIEC Census Report - Summary Census Demographic Information" from the FFIEC website using only Pandas, you will get an error 403.
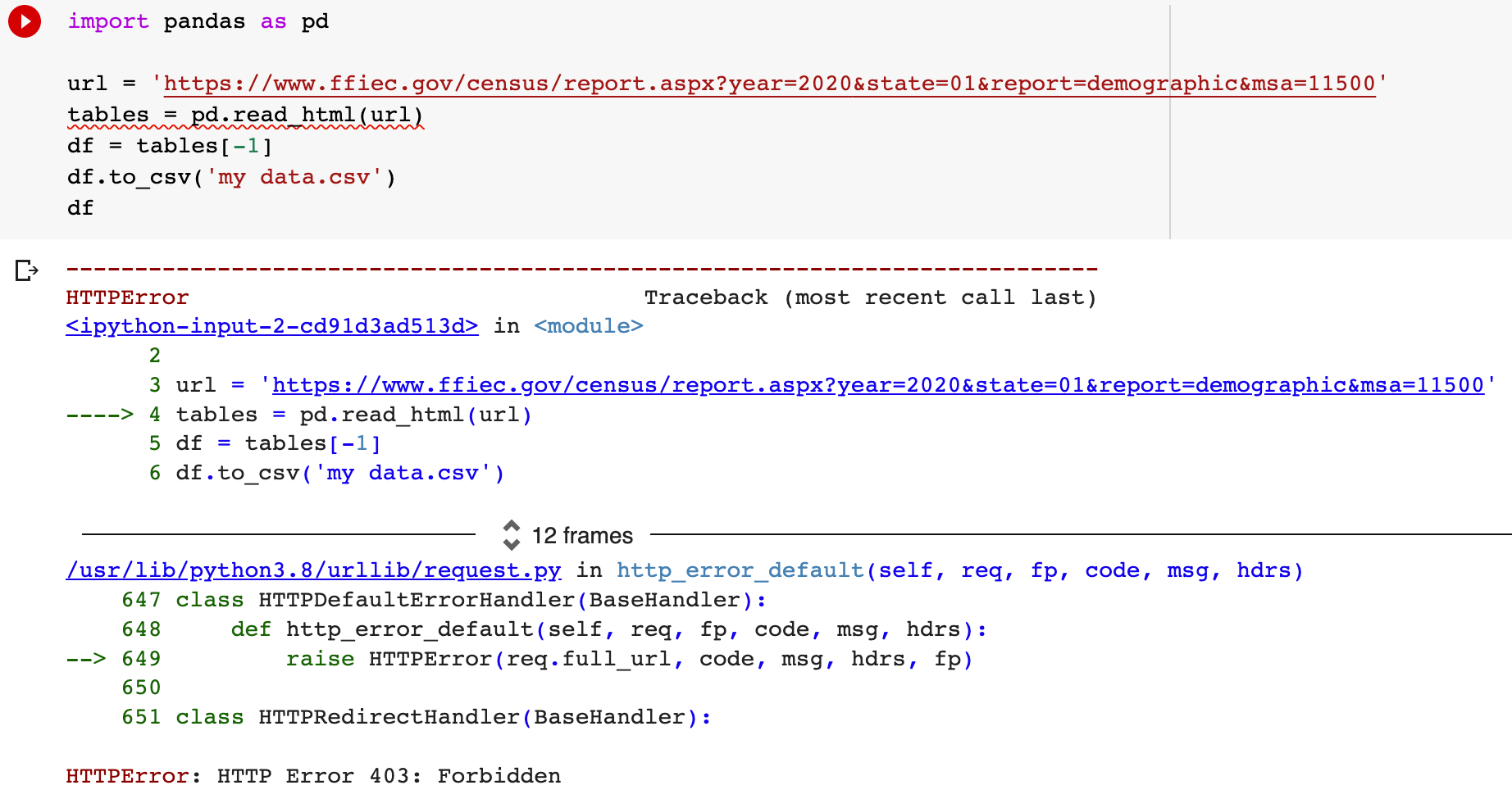
You can get around a 403 error by using the requests library in conjunction with the pandas read_html() function.
import requests
import pandas as pd
url = 'https://www.ffiec.gov/census/report.aspx?year=2020&state=01&report=demographic&msa=11500'
#get html first with get function from requests lib
html = requests.get(url).content
#pass html into read_html() function
df_list = pd.read_html(html)
#index -1 will get you the last table available on the page
df = df_list[-1]
#save to csv file
df.to_csv('my data.csv')
print(df)
Conclusion
This demonstrates that using pd.read_html() is a straightforward way of scraping data from webpages, as Pandas uses BeautifulSoup4 and html5lib on the backend, which can be beneficial for simple data scraping projects. However, if you want to be able to scrape any website on the web, you will need to learn much more about scraping. Hehe, learning never stops, just like web development.