
Frustrated by not finding a suitable dataset? — Why not just create your own using Faker? In case you do not know about the library used in this article, Faker is a Python package that generates fake data for you. It has a rich set of predefined providers and generators for all sorts of data. This article will help you get started with Faker, talk about its rich built-in providers and generators, walk you through writing your own providers, and go over some good practices related to the use of faker.
What we will create using Python and Faker?
Here we will create a dataset for an imaginary telephone directory of businesses based in the UK.
Our fictional directory has structured data such as:
- Unique ID,
- UK companies registration number,
- Company Name,
- Companies contacts firstname,
- Companies contacts surname,
- Companies address,
- Postcode,
- and Phone.
Let’s get started making our fake yellow pages dataset! No need to scrape actual websites of business directories and break laws just to get some test data for your educational needs.
Here is how you can make a dataset with some dummy data using Python and Faker.
How do I make a fake dataset in Python with Faker?
1.) Install Faker package
We will use Python package called Faker to get started. Faker can be described as “a Python package that generates fake data for you.” By using this package we will save ourselfs time by not writing our own functions that will generete for us rundom fake values.
Faker is easily installable via pip install. To install the Faker package use the pip command as follows:
pip install Faker
2.) Initialize Faker Generator
Let’s initialize a faker generator and start making some data:
from faker import Faker
fake = Faker()
Now you are done with the installation and initialization of a Faker generator, and everything is ready for you to create any data you want.
3.) Get your head around Faker Providers and Localizations.
3.a - What is a Faker provider?
fake = Faker() initializes a fake generator which can generate data for different properties based on different data types. Different properties of faker generator are packaged in “providers”. Full list of different faker providers can be found here.
Some of the fake generators for different data types are illustrated below. More detailed use of different providers is given in this notebook.
3.a - What is a Faker localization?
Localization allows users to specify data for which location they need Faker package to return. This is important because a list of random Firstnames and Lastnames in US would be diffrent to a list of random Firstnames and Lastnames in Japan.
faker.Faker() can take a locale as an argument, to return localized data. Default locale is en_US. It has support for variouse languages and locations. Faker supports languages like Hindi, French, Spanish, Chinese, Japanese, Arabic, German and many more.
In this article we are generating fake dataset with UK companies data, so we will need Faker localization for UK.
To generate UK fake data we will use localization called en_GB.
uk_faker = Faker('en_GB')
4.) Identify Faker properties that generate the data you are after.
Desired data sample should have columns with the following data: Unique ID, UK companies registration number, company name, companies contacts firstname, companies contacts surname, companies address, postcode, and phone. Let's see how we can generate it using Python and Faker.
You will find below faker properties or methods that will help us build profiles for the UK companies.
You will need to have uk_faker at the beginning for properties that are comming from the localization called en_GB and fake for default localization en_US. Remember that we initialized fake generators as uk_faker = Faker('en_GB') and fake = Faker().
UK Company ID: fake.ean8()
Company Name: fake.company()
Contacts Firstname: uk_faker.first_name()
Contacts Firstname: uk_faker.last_name()
UK Adress: uk_faker.address()
UK Postcode: uk_faker.postcode()
Phone: uk_faker.phone_number() or f'+44 {fake.msisdn()[3:]}'
You can get an idea of how the fake data would look like for each method by printing n number of results in your Jupyter Notebook using for i in range(<number or results you need>).
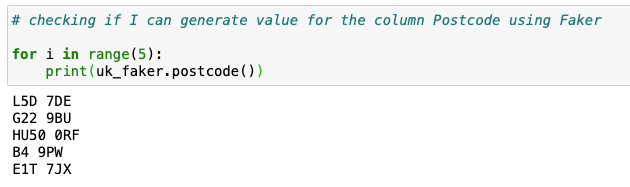
5.) Check that data provided by Faker properties returns the type of data you want.
This will give you an idea if the data generated by the method you used is suitable for your needs or not. In order to test output you will need to print more than one returned value bucause values generated by Faker can vary a bit. Here is the exsample of such behaviour.
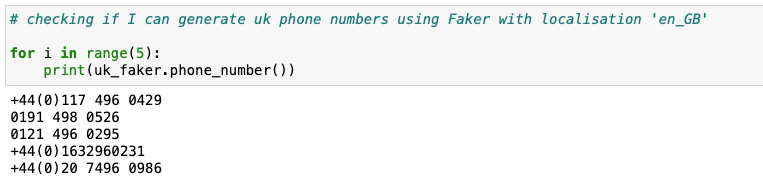
As we can see uk_faker.phone_number() generates UK phone numbers but they are not in the same format. If you need phone number that is in the format +44 xxxxxxxxxx you can generate it using f'+44 {fake.msisdn()[3:]}'. Here we define that the start of our phone number is always +44 and generate random ten digits after it with fake.msisdn()[3:].
You will also need to note that values returned byuk_faker.address() have \n in them. This will cause issues during the writing process to the csv.
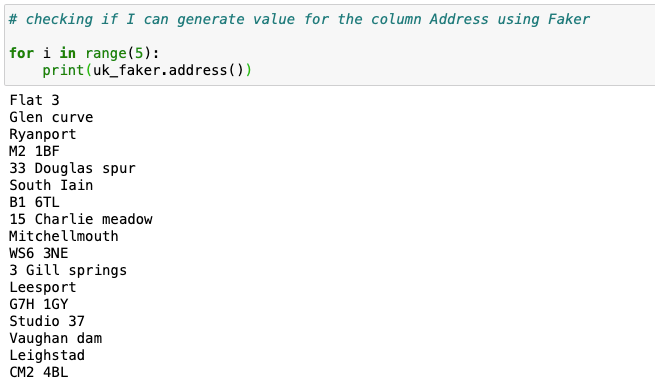
Fixing this issue is very easy. All you have to do is to replace "\n" with the ", " - uk_faker.address().replace("\n", ", ")

Outputs for other methods returned data as expected. These are looking good! Let’s put everything together and create our fake UK companies directory dataset!
6.) Write fake data generated via Python and Faker to a csv file using CSV Python library.
So it is time to create a csv file with the desired fake data. For this you will need to import python library called csv that will make possible writing to the csv file, initialize a faker generator, define localization, specify how many records do you want to have in your dataset in the cvs file, and finally write to the csv file values returned by the Faker properties that we selected earlier.
Here is the script to do just that.
import csv
import random
from faker import Faker
fake = Faker()
uk_faker = Faker('en_GB')
RECORD_COUNT = 100
def writeTo_csv():
with open('my_fake_data_v2.csv', 'w', newline='') as csvfile:
fieldnames = ['ID', 'Company_ID', 'Company_Name', 'Firstname', 'Surname', 'Address', 'Postcode', 'Phone']
seed = 0
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for i in range(RECORD_COUNT):
seed += 1
writer.writerow({"ID": seed, "Company_ID": fake.ean8(), "Company_Name": fake.company(), "Firstname": uk_faker.first_name(), "Surname": uk_faker.last_name(), "Address": uk_faker.address().replace("\n", ", "), "Postcode": uk_faker.postcode(), "Phone": f'+44 {fake.msisdn()[3:]}' })
if name == 'main':
writeTo_csv()
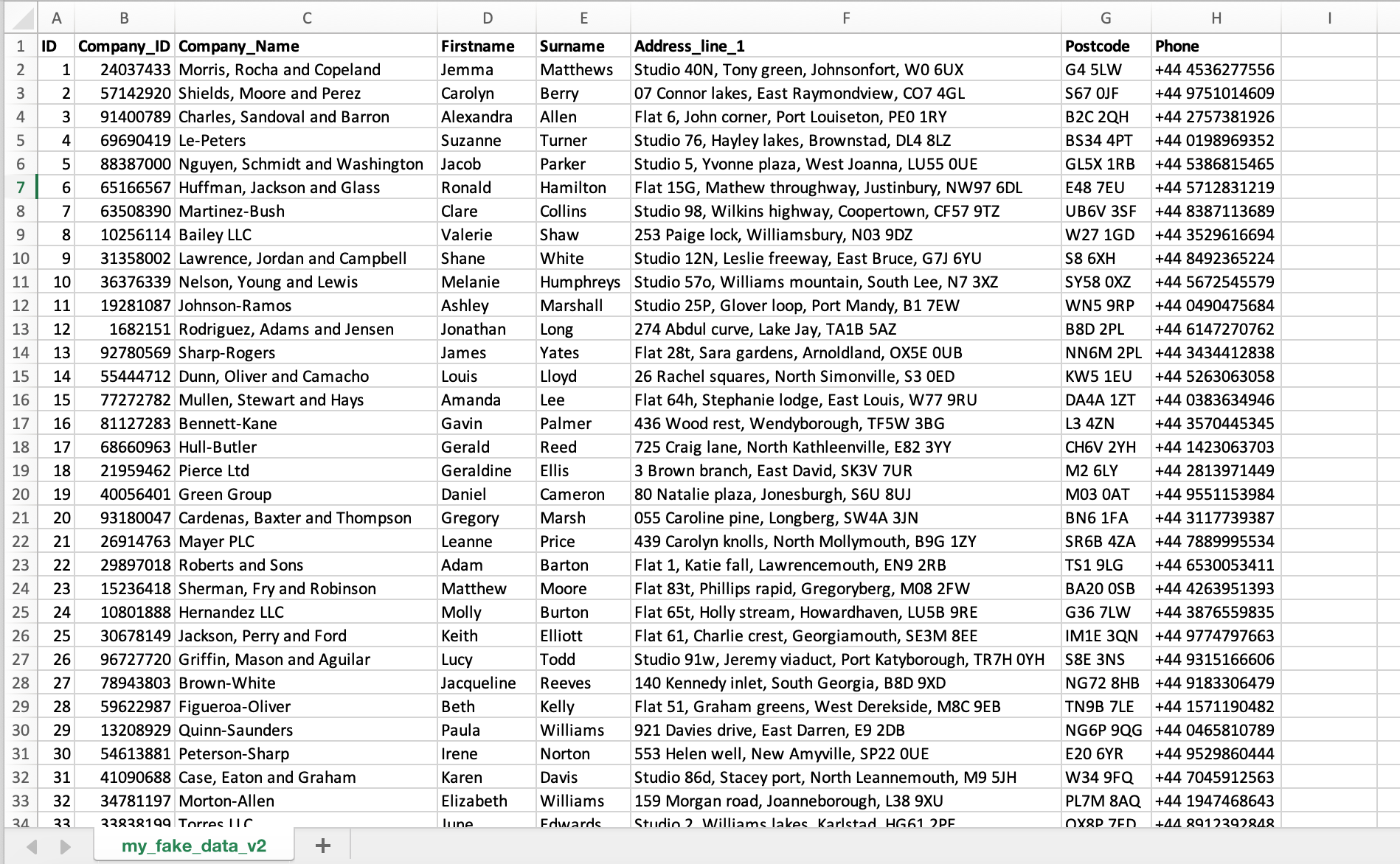
Success!