Pandas is a great Python library for data analytics as it makes it relatively simple, but in some cases very simple data modifications that are super simple to make in Excel can be not so straightforward in Pandas. For example, to add a row at the top in Pandas dataframe you need to run multiple commands. Here is a detailed explanation of how you can add a row at the top in Pandas dataframe.
What we want to achieve
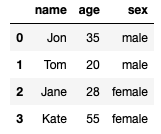
Let's say that below is our dataframe to which we want to add a row at the top (at index 0):
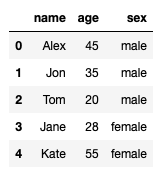
We want to insert a new row at the first position with the following data - name: Alex, age: 45, sex: male. We want to get the following dataframe:
Solution 1: using list and pd.concat()
This can be done by gathering the new data into a list first and then use pd.concat([], ignore_index=True) to add it at the top (at index 0) of dataframe.
Please see exsample code below:
# importing pandas
import pandas as pd
# creating a simple dataframe
df = pd.DataFrame({'name': ['Jon','Tom','Jane','Kate'],
'age': [35,20,28,55],
'sex':['male','male','female','female']})
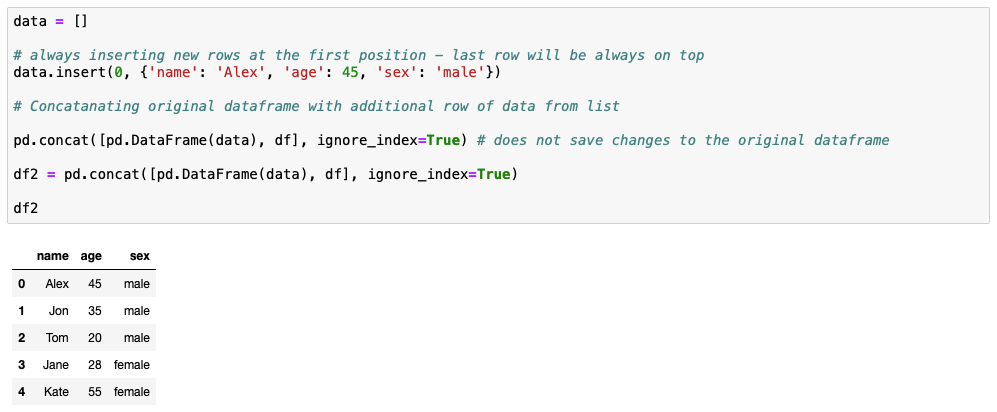
data = []
# always inserting new rows at the first position - last row will be always on top
data.insert(0, {'name': 'Alex', 'age': 45, 'sex': 'male'})
# Concatanating original dataframe with additional row of data from list
pd.concat([pd.DataFrame(data), df], ignore_index=True) # does not save changes to the original dataframe
# Saving modified df as df2
df2 = pd.concat([pd.DataFrame(data), df], ignore_index=True)
df2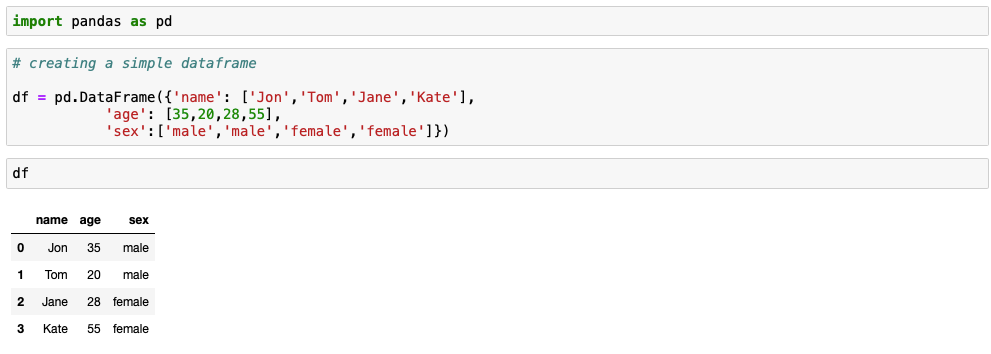
Solution 2: using loc, index, and sort_index(inplace=True)
Another way to solve this challenge is by assigning a row to a particular index, using loc to incert data with index -1 and then modify indexes by adding 1 to all row indexes, so row with index -1 becomes 0 and row that had index 0 changes to
Remember that ealier record for Alex was added to df2, hence why we are adding row for Dean to df2.
# remember that df was not modified by code above. Record for Alex was added to df2
# another way of adding a row to the top of Pandas dataframe
df2.loc[-1] = ['Dean', '25', 'male'] # adding a row
df2.index = df2.index + 1 # shifting index
df2.sort_index(inplace=True) 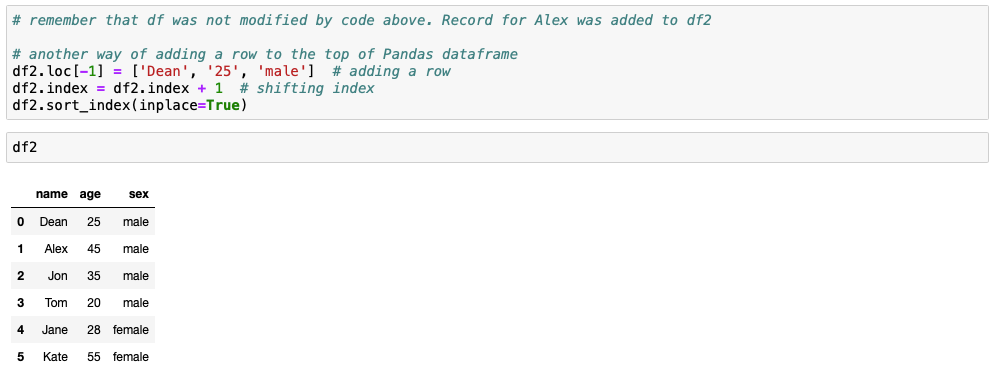
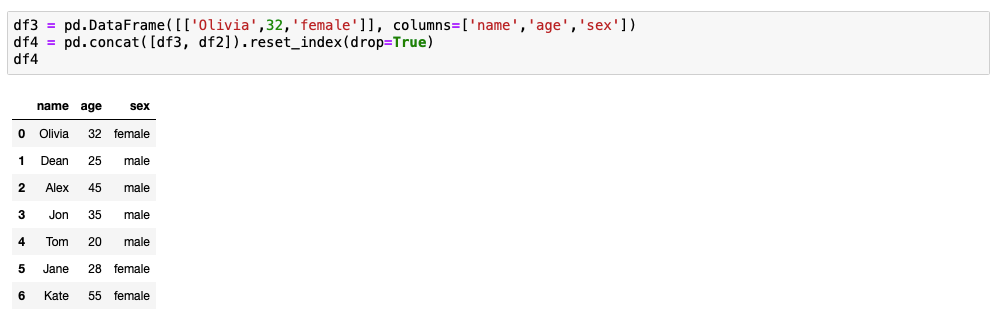
Solution 3: using additional dataframe and pd.concat() with .reset_index(drop=True)
This solution is very similar to solution 1, we just replace list with additional dataframe than use pd.concat together with .reset_index(drop=True). Don't forget to use .reset_index(drop=True) or you will end up with two rows set to index 0.
# adding row to dataframe at index 0 via additional dataframe and pd.concat
df3 = pd.DataFrame([['Olivia',32,'female']], columns=['name','age','sex'])
df4 = pd.concat([df3, df2]).reset_index(drop=True)
df4