
If you need a refresher on how Regular Expressions work, check out my RegEx guide first! This tutorial will walk you through pattern extraction from one Pandas column to another using detailed RegEx examples.
When I was doing data cleaning for a scraped rose data, I was challenged by a Regex pattern two digits followed by to and then by two digits again. I was surprised that I could not find such a pattern/Regex on the web, so here is an explainer. Plus a few other Regex examples that I had to create to clean my data.
Sample dataframe
Let's create a simplified Pandas dataframe that is similar to the one I was cleaning when I encountered the Regex challenge. In the dataframe, we have a column BLOOM that contains a number of petals that we want to extract in a separate column. A number of petals is defined in one of the following ways:
- 2 digits to 2 digits (26 to 40),
- 2 digits - 2 digits (26-40),
- as text inside brackets (26-40 petals),
- or as 2 digits petals.
# initialize list of lists
data = [['Evert van Dijk', 'Carmine-pink, salmon-pink streaks, stripes, flecks. Warm pink, clear carmine pink, rose pink shaded salmon. Mild fragrance. Large, very double, in small clusters, high-centered bloom form. Blooms in flushes throughout the season.'],
['Every Good Gift', 'Red. Flowers velvety red. Moderate fragrance. Average diameter 4". Medium-large, full (26-40 petals), borne mostly solitary bloom form. Blooms in flushes throughout the season.'],
['Evghenya', 'Orange-pink. 75 petals. Large, very double bloom form. Blooms in flushes throughout the season.'],
['Evita', 'White or white blend. None to mild fragrance. 35 petals. Large, full (26-40 petals), high-centered bloom form. Blooms in flushes throughout the season.'],
['Evrathin', 'Light pink. [Deep pink.] Outer petals white. Expand rarely. Mild fragrance. 35 to 40 petals. Average diameter 2.5". Medium, double (17-25 petals), full (26-40 petals), cluster-flowered, in small clusters bloom form. Prolific, once-blooming spring or summer. Glandular sepals, leafy sepals, long sepals buds.'],
['Evita 2', 'White, blush shading. Mild, wild rose fragrance. 20 to 25 petals. Average diameter 1.25". Small, very double, cluster-flowered bloom form. Blooms in flushes throughout the season.']]
# Create the pandas DataFrame
df = pd.DataFrame(data, columns = ['NAME', 'BLOOM'])
# print dataframe.
df 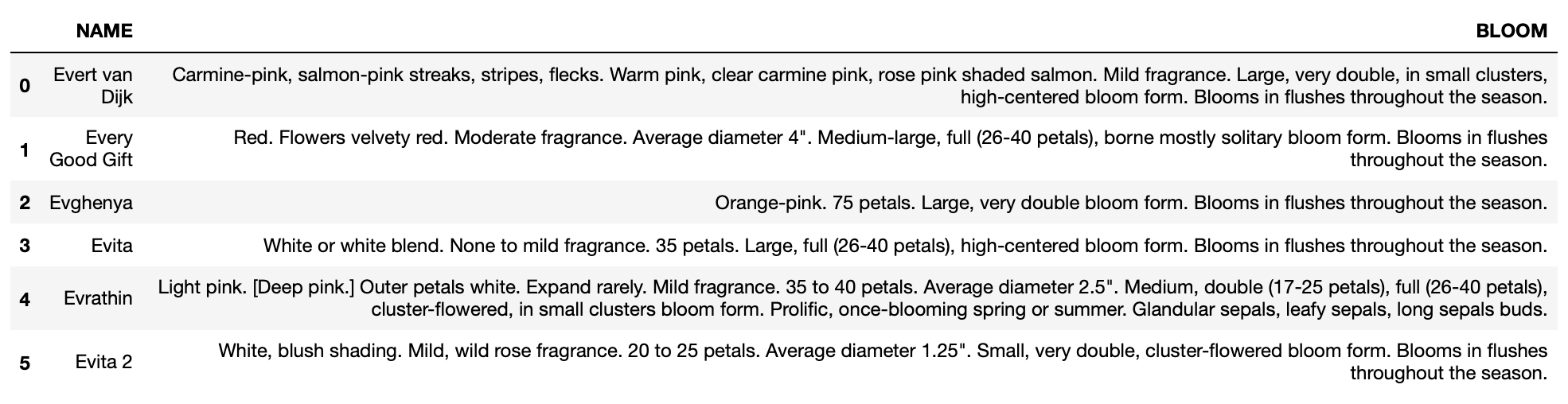
Pandas extract column
If you need to extract data that matches regex pattern from a column in Pandas dataframe you can use extract method in Pandas pandas.Series.str.extract. This method works on the same line as the Pythons re module. It's really helpful if you want to find the names starting with a particular character or search for a pattern within a dataframe column or extract the dates from the text.
Pandas extract syntax is Series.str.extract(*args, **kwargs)
Parameters:
- pat (str) - Regular expression pattern with capturing groups.
- flags (int), default 0 (no flags) -Flags from the
remodule, e.g.re.IGNORECASE, that modify regular expression matching for things like case, spaces, etc. For more details, seere. - expand (bool), default True - If True, return DataFrame with one column per capture group. If False, return a Series/Index if there is one capture group or DataFrame if there are multiple capture groups.
RegEx examples
When I started to clean the data, my initial approach was to get all the data in the brackets.
- Regex for text inside brackets like (26-40 petals) -
(\\(.*?)\\)or as raw string asr'(\(.*?)\)'
#coping content in column BLOOM inside
#first brackets into new column PETALS
df['PETALS'] = df['BLOOM'].str.extract('(\\(.*?)\\)', expand=False).str.strip()
df['PETALS'] = df['PETALS'].str.replace("(","")
#same as above but regex defined as raw string
df['PETALS_R'] = df['BLOOM'].str.extract(r'(\(.*?)\)', expand=False).str.strip()
df['PETALS_R'] = df['PETALS_R'].str.replace("(","")
# #coping content in column BLOOM inside all brackets into new column ALL_PETALS_BRACKETS
df['ALL_PETALS_BRACKETS'] = df['BLOOM'].str.findall('(\\(.*?)\\)')
df[['NAME','BLOOM','PETALS', 'PETALS_R', 'ALL_PETALS_BRACKETS']]
Then I realised that this method was not returning to all cases where petal data was provided. For example, row 5 has entry 20 to 25 petals that is not in brackets. While row 4 has entry 35 to 40 petals as well as two brackets containing a number of petals for various types of bloom.
Such patterns we can extract with the following RegExs:
- 2 digits to 2 digits (26 to 40) -
r'(\d{2}\s+to\s+\d{2})' - 2 digits - 2 digits (26-40) -
r'(\d{2}-\d{2})' - or as 2 digits followed by word "petals" (35 petals) -
r'(\d{2}\s+petals+.)'
In above RegExs I use:
rto mark my RegEx (string) as a raw string, which does not escape metacharecters.\d- Matches any decimal digit. Equivalent to any single numeral 0 to 9.{}- Whatever precedes braces{n}will be repeated at least n times.\s- Matches where a string contains any whitespace character. Equivalent to any space, tab, or newline charecter. (Think of this as matching "space" charecters.)
# ?<! is for negative look behind
# works on sample df but not on the df with my scraped data
df['PETALS1'] = df['BLOOM'].str.extract(r'(?<!\d)(\d{2}\s+to\s+\d{2})\s*petal', expand=False)
# modification that works on our sample df and on my main df.
# now lets copy part of column BLOOM that matches regex patern two digits to two digits
df['PETALS2'] = df['BLOOM'].str.extract(r'(\d{2}\s+to\s+\d{2})', expand=False).str.strip()
# also came across cases where pattern is two digits followed by word "petals"
#now lets copy part of column BLOOM that matches regex patern two digits followed by word "petals"
df['PETALS3'] = df['BLOOM'].str.extract(r'(\d{2}\s+petals+\.)', expand=False).str.strip()
# now lets copy part of column BLOOM that matches regex patern two digits hyphen two digits followed by word "petals"
df['PETALS4'] = df['BLOOM'].str.extract(r'(\d{2}-\d{2}\s+petals)', expand=False).str.strip()
df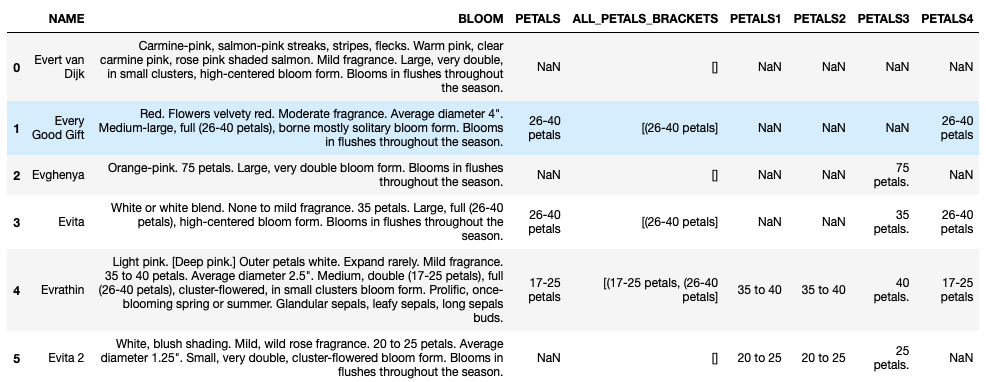
Hurrah, we have petals data extracted in separate columns.
Now let's create one master column for petals data. In this case, the master column will be column PETALS1.
This loop will replace null in column PETALS1 with value in column PETALS4.
# if column PETALS1 is null then replace
# with value in column PETALS4
for i, row in df.iterrows():
if (pd.isnull(row['PETALS1'])):
row['PETALS1'] = row['PETALS4']
df[['BLOOM','PETALS', 'PETALS2', 'PETALS3', 'PETALS4','ALL_PETALS_BRACKETS','PETALS1']]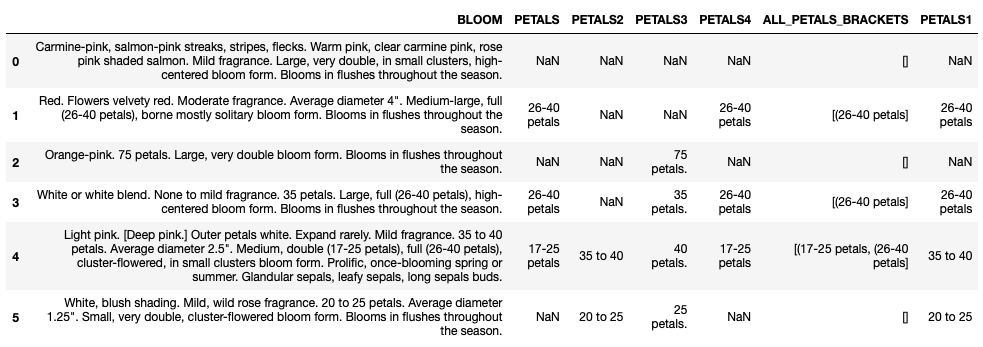
This loop will replace null in column PETALS1 with value in column PETALS3.
# if column PETALS1 is still null then replace
# with value in column PETALS3
for i, row in df.iterrows():
if (pd.isnull(row['PETALS1'])):
row['PETALS1'] = row['PETALS3']
df[['BLOOM','PETALS', 'PETALS2', 'PETALS3', 'PETALS4','ALL_PETALS_BRACKETS','PETALS1']]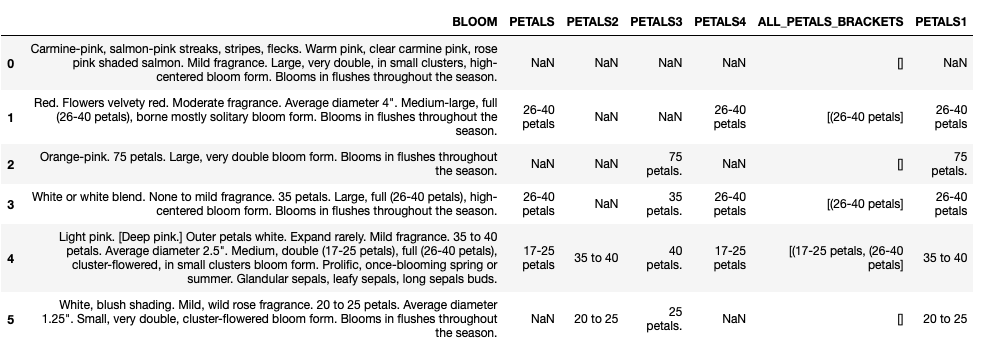
Do your happy dance. Now you have all petals data in column PETALS1 that is available in column BLOOM. I hope that those examples helped you understand RegExs better.